
The Experts Guide for Using Entity-Based SEO to Boost Your Search Rankings
There’s a lot of chat circulating around the SEO communities about Entity Based SEO and what it is! That’s why we have gone ahead and created the last article you will ever need to read about it, and even more-so how to start implementing it today
Grab a coffee and throw on your favorite music compilation, because you may be here for a while
In essence, entity-based SEO is a concept that focuses on optimizing a website for entities, rather than just keywords. If you remember, we’ve previously discussed that an entity is a person, place, or thing that can be identified and labeled, such as a celebrity, brand, product, business, organization, and so forth
Traditionally in the past, SEOs have focused on optimizing a website for specific keywords in order to rank higher in search engine results. However, this approach has limitations, as it doesn’t always accurately reflect the intent of the user’s search query. For example, if a user searches for “iPhone,” they may be looking for information about the brand, the product, or a specific model
Entity-based SEO on the other hand takes a more holistic approach by focusing on the entities (nouns) that are relevant to the user’s search query. By understanding the entities that are related to a particular keyword, a website can provide more accurate and relevant information to the user
By providing users with more accurate and relevant information, they are more likely to stay on the website longer, which can improve engagement and reduce bounce rates. This can also improve the website’s ranking in search engine results, as search engines prioritize websites that provide a good user experience and comprehensive content surrounding all facets of any given entity as a whole
In addition, through the focus of entities that are relevant to the user’s search query, a website can rank for a wider range of keywords and long-tail phrases. This can help the website attract more organic traffic, which can lead to more leads and sales
In order to implement entity-based SEO, it’s important to first identify the entities that are relevant to the website’s content. This can be done by using tools such as Google’s Knowledge Graph or the Open Calais API. Once the relevant entities have been identified, the website’s content can be optimized to include these entities and their related keywords
How Entities Are Determined & Connected Through Search Engines for SEO
In search engines, entities are determined by a combination of algorithms and human input
One of the key ways that entities are determined is through the use of natural language processing algorithms designed and developed by multiple resources
These algorithms analyze the words and phrases in a user’s search query and identify the entities (nouns) that are mentioned. This is done by analyzing the context and relationships between the words and phrases in the query and matching them to known entities in the search engine’s database of known relational entities.
Note: a relational entity is any entity that has a relation to another entity. An example of this would be as plumbing is to pipes, or water is to bottle
Another way that entities are determined is through the use of structured data sets and schema implementation. Structured data is information that is organized in a specific format, such as JSON-LD or microdata, and is embedded in a website’s HTML code. This data provides search engines with additional information about the entities that are mentioned on the website, such as their names, descriptions, and relationships to other entities.
In some cases, over time, entities can also be determined through human input. This can include things like
- User-generated content, such as reviews and ratings
- Information that is provided by external sources, such as databases
- You guessed it local SEO guys – directories
Overall, search engines use a combination of algorithms and human input to determine the entities that are relevant to a user’s search query. This allows them to provide users with more accurate and relevant search results
How To Identify & Write Content for Entity-Based SEO
One of the most frequent questions we get is “How do I identify entities”, and rightfully so. When looking to create a website, page or blog/article it’s important to make note of primary entities and relational entities
We’ve broken the process down for you in only a few steps below to help you get started today
#1 Identify the primary entities that are relevant to the website’s content. This can be done by using tools such as Google’s Knowledge Graph or the Open Calais API to identify people, places, and things that are related to the website’s topic.
When looking to identify primary entities, we fall back on linguistic syntax and the understanding of language
Going back to our example of plumbing, here is a list of the primary entities:
- Plumbing
- Plumber
Note: When creating content around your entity, you want to teach Google that your business entity/name is associated with the service being provided
In the use case above, you may do this by using headlines and content constructed with the sole purpose of building entity relationships. Interesting enough, our mind works the same way.
Think about it this way, if someone came up to you and said “Can you recommend a plumber in the local area”, a lot of us would already have a business in mind – also known as a relational entity
Bonus tip, you can now create a proposed sitemap in Chat GPT 3 using the following command that will help to identify the top services and their entities:
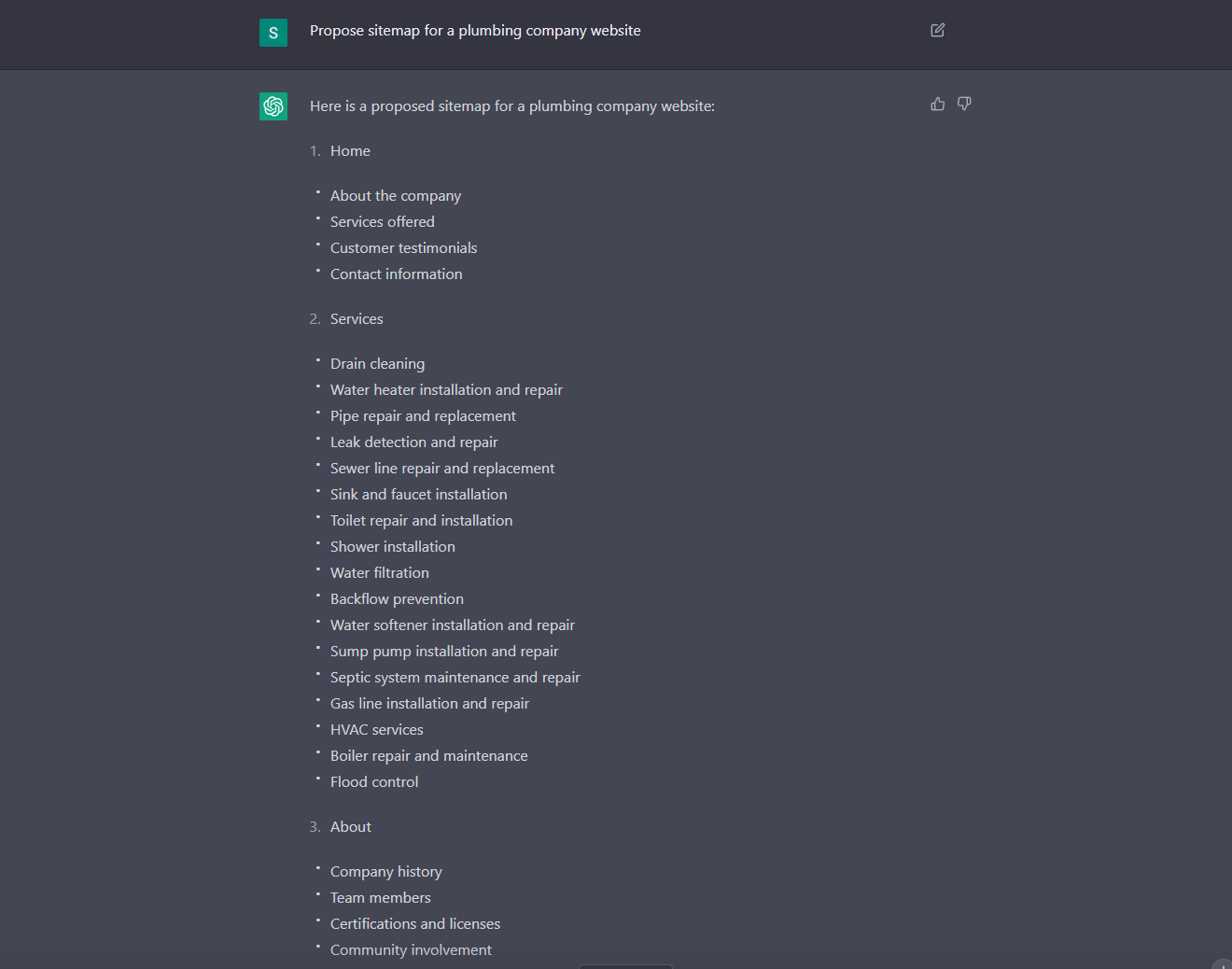
#2 Research relational entities and their degrees of separation to gather more information about them. This will help you understand the context and significance of the entities, and will provide you with ideas for related keywords and phrases
To properly identify a primary entity, it’s important to look at the root word that will be used throughout the content of a website, and the context it provides
For example, if we were creating a Plumbing website, the root entity would be Plumbing with relational entities being:
- Toilet
- Pipe
- Water
- Bathroom
- Kitchen
- Sink
- House
- Commercial
- Residential
- Business Name
To find these, you simply can pop over to Google Images, type in your entity and begin to filter through the results in Google’s image carousel. Alternatively, another option is to use CHAT GPT3 with the following command to generate entities for a keyword:
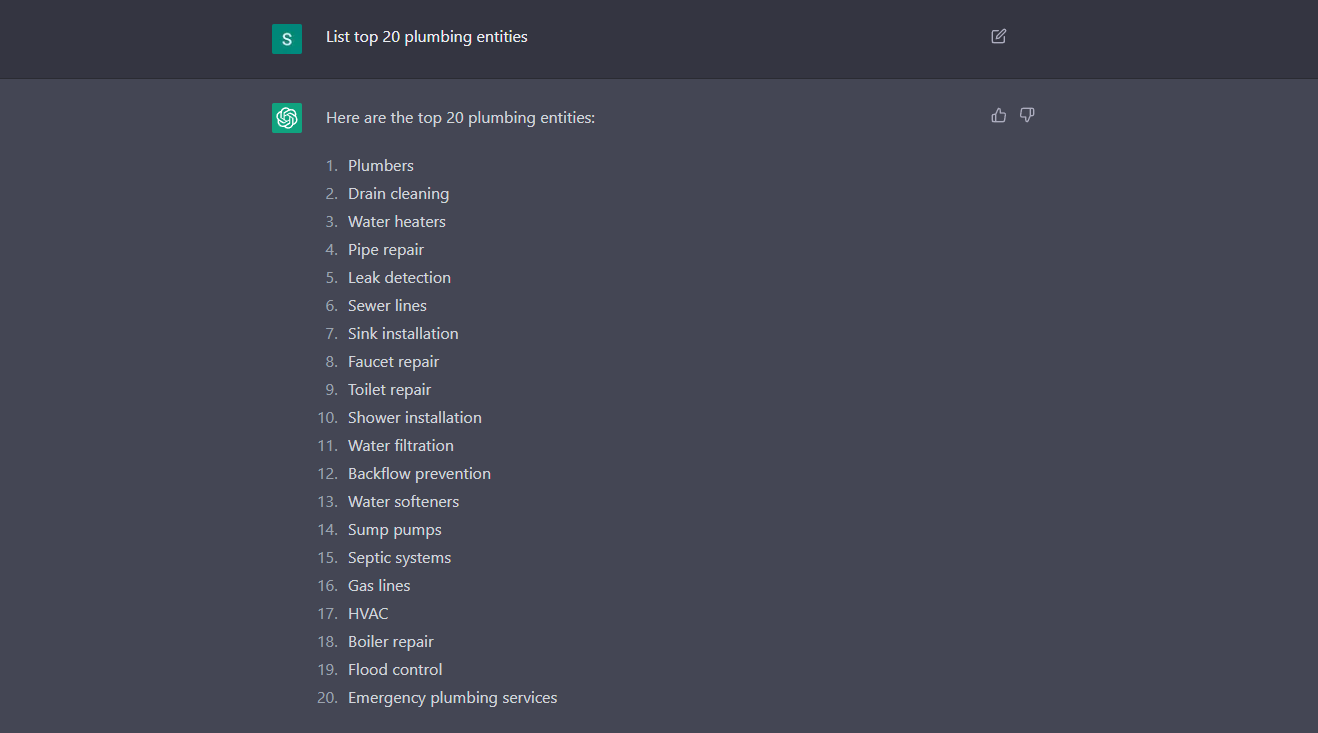
#3 Create a list of keywords and phrases that are related to those entities. This will be the foundation of your entity-based SEO strategy, as these keywords and phrases will help search engines understand the context and relevance of your content.
To complete this process in Chat GPT use the following command to generate relational entities to the auxiliary services mentioned in the screen shot above when creating new pages:
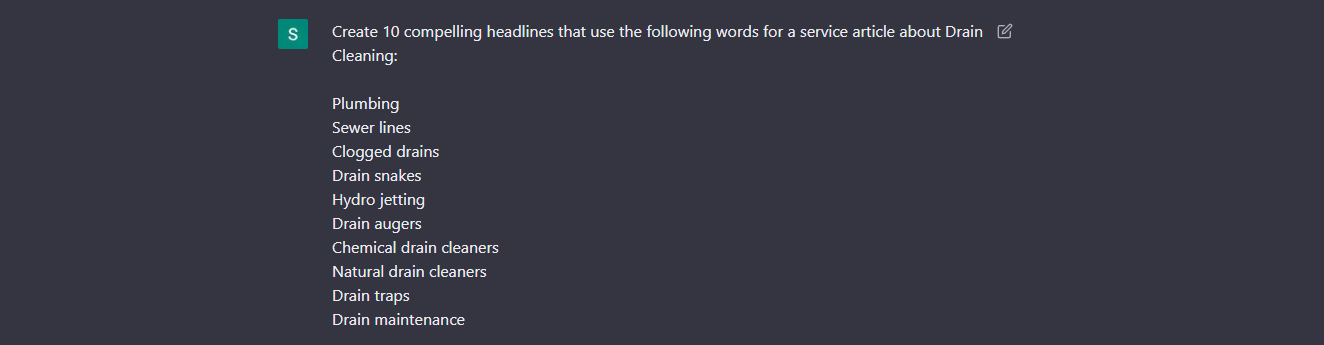
#4 Write the website content, incorporating the entities and their related keywords and phrases. Make sure to use the entities and their related keywords and phrases throughout the content, including in the title, headings, and body of the text.
Next, we focus on crafting the verbiage of the page to utilize these entities and relational entities to give Google a comprehensive understanding of what the page and website is about
Using the above information in the entity spreadsheet or Chat GPT we can begin constructing headlines such as
In thee below examples we are associating known entities with one another so that Google has a complete understanding of what the document should be indexed for
Here is how to use Chat GPT to generate and construct headlines for you with known entities using the following command:
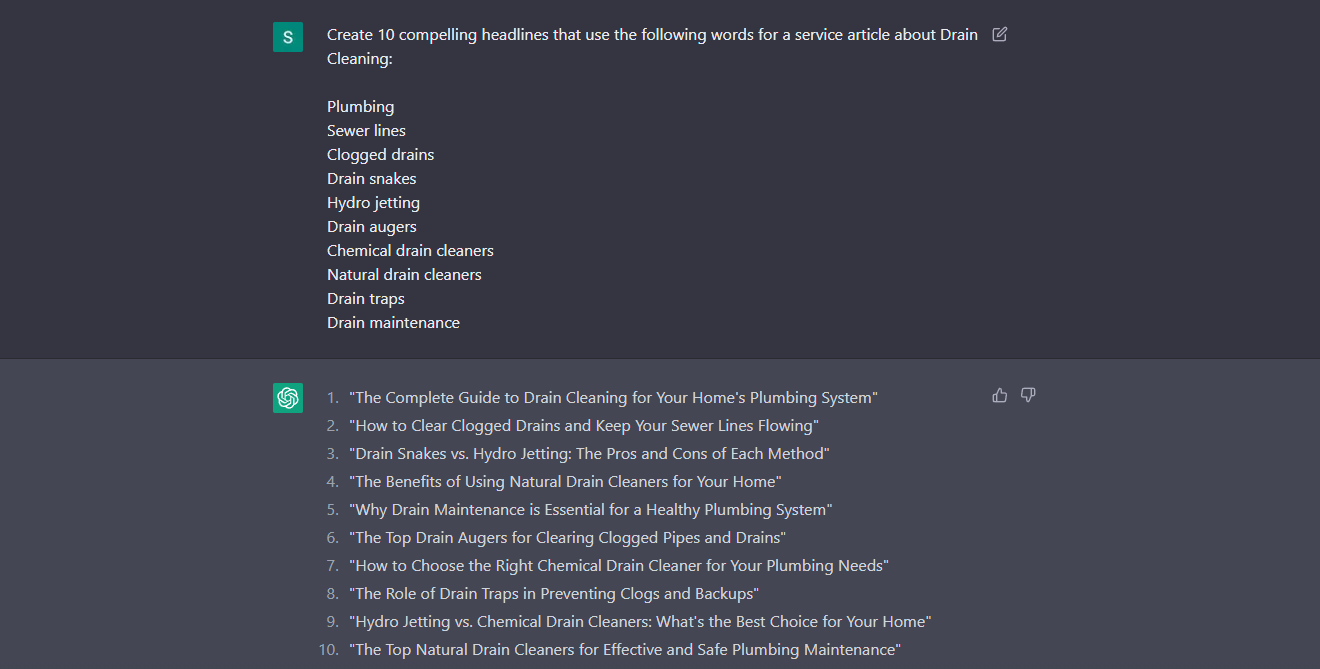
When the above steps are combined seamlessly, it’s easy to create a comprehensive structure of entities when implementing them into your on-page structure and overall website schema!
With the launch of the helpful content update, we also take the steps below to gear your content just as much toward users as search engines:
- Identify the needs and interests of your audience. Before you start writing, take some time to understand who your audience is and what they are looking for. This will help you create content that is relevant and useful to them.
- Use a clear and concise writing style. Avoid using jargon or complex language, and make sure to break up your text into easily-digestible sections, such as headings and subheadings.
- Provide practical and actionable information. Instead of just providing general information, focus on providing specific, practical advice that your readers can use to solve a problem or achieve a goal.
- Use examples and case studies to illustrate your points. This will help make your content more relatable and engaging and will provide your readers with concrete examples of how your advice can be applied in real-world situations.
- Use images, videos, and other visual elements to enhance your content. This will help break up the text and make your content more visually appealing, which can improve engagement and retention.
How Natural Language Processing Works Hand In Hand With Entity-Based SEO
There is no specific algorithm that is used for natural language processing. Instead, natural language processing is a field of artificial intelligence that involves a combination of various algorithms and techniques.
Some of the key algorithms and techniques used in natural language processing include:
#1 Part-of-speech tagging: This involves identifying the parts of speech, such as nouns, verbs, and adjectives, in a sentence or phrase.
Approaches to Part-of-Speech Tagging Include The following:
The first approach to part-of-speech tagging is to use a supervised machine learning algorithm, such as a hidden Markov model or a conditional random field. This involves training the algorithm on a large corpus of annotated text, where the parts of speech have been labeled. The algorithm then uses this training data to learn the patterns and rules that are used to identify the parts of speech in new text.
Another approach to part-of-speech tagging is to use a rule-based natural language processing system, which uses a set of rules and patterns to identify the parts of speech in a text. This approach can be more accurate, but it requires a significant amount of time and effort to develop the rules and patterns, and it may not be as flexible or adaptable as a machine learning approach.
#2 Named entity recognition: This involves identifying and labeling specific entities, such as people, places, and organizations, in a text.
Approaches to Named Entity Recognition Include The Following:
The first approach to named entity recognition is to use a supervised machine learning algorithm, such as a support vector machine (SVM) or a conditional random field. This involves training the algorithm on a large corpus of annotated text, where the entities have been labeled. The algorithm then uses this training data to learn the patterns and rules that are used to identify entities in new text.
Another approach to named entity recognition is to use a rule-based natural language processing system, which uses a set of rules and patterns to identify entities in a text. This approach can be more accurate, but it requires a significant amount of time and effort to develop the rules and patterns, and it may not be as flexible or adaptable as a machine learning approach.
#3 Dependency parsing: This involves analyzing the grammatical structure of a sentence or phrase, and identifying the relationships between the words, such as subject-verb-object.
Approaches to Dependency Parsing Include The Following:
The first approach to dependency parsing is to use a supervised machine learning algorithm, such as a recurrent neural network or a graph-based parser. This involves training the algorithm on a large corpus of annotated text, where the dependencies between words have been labeled. The algorithm then uses this training data to learn the patterns and rules that are used to identify the dependencies between words in the new text.
Another approach to dependency parsing is to use a rule-based natural language processing system, which uses a set of rules and patterns to identify the dependencies between words in a text. This approach can be more accurate, but it requires a significant amount of time and effort to develop the rules and patterns, and it may not be as flexible or adaptable as a machine-learning approach.
#4 Sentiment analysis: This involves analyzing the emotional content of a text, and determining whether it is positive, negative, or neutral.
Conclusion About Entity-Based SEO
In conclusion, the future of entity-based SEO is likely to be a combination of both traditional SEO and entity-based SEO. As search engines continue to evolve and improve their algorithms, they will become better at understanding the context and relationships between entities and will be able to provide users with more accurate and relevant search results as time goes on.
At the same time, traditional SEO techniques, such as keyword optimization and on-page optimization, will continue to be important for improving how relational entities exist on the website itself.
By embracing both approaches, websites will be able to provide a better user experience and improve their visibility in search engine results for years to come.
People Also Ask About Entity Based SEO
When Were Entities First Introduced to Search Engines and SEO
The concept of entities in search engines has been around for many years, but they were first introduced as a major part of search engine algorithms in 2012, when Google introduced the Knowledge Graph
The Knowledge Graph is a database of over 1 billion entities, which allows Google to provide users with more accurate and relevant search results. For example, when a user searches for “iPhone,” the Knowledge Graph will provide information about the brand, the product, and specific models, rather than just a list of websites that contain the keyword “iPhone.”
Since the introduction of the Knowledge Graph, other search engines, such as Bing and Yahoo, have also started using entities in their algorithms. This has led to a shift in the way that search engines understand and process user queries, and has made it more important for websites to optimize for entities in order to improve their visibility in search engine results.
What Is The Difference Between Conventional Keyword SEO and Entity Based SEO
When it comes to entity based SEO, there are some key differences in how it differs from conventional keyword based SEO
While the primary function of ranking a page remains the same, the techniques used are different
In conventional keyword based SEO pages are created to capitalize on the search traffic of individual keywords. In many cases you would see the keyword placed in different parts of the contextual information at a specific ratio known as “Keyword Density”
In entity based SEO we still use our keywords but also use relational entities in conjunction with our keywords
Here is how you may write an intro line for a Plumber in Chicago utilizing conventional keyword based SEO:
As a Plumber in Chicago, we offer around the clock plumbing services from our team of professional plumbing experts!
And here is how you may write the same sentence using Entity Based SEO:
When it comes to looking for an experienced Chicago Plumber that you trust in your home, ACME Company is the professional service repair company of choice – just ask your neighbors and friends!
As you can see between the two examples, one sentence is focusing primarily on keywords and the other on relational entities that not only help search engines to understand your comprehensive landscape, but to also provide a better reading experience for your traffic
What Is a Support Vector Machine And How Does It Help SEO With Entities?
A support vector machine (SVM) is a type of machine learning algorithm that is commonly used in the field of search engine optimization (SEO)
In the context of SEO, an SVM can be used to classify and predict the relevance of a website’s content to a particular user query. For example, an SVM could be trained on a large corpus of labeled data, where the relevance of each website’s content to a particular query has been labeled. The SVM could then be used to predict the relevance of new content to that query, based on its similarity to the training data
The SVM algorithm starts by mapping the input data points to a higher-dimensional space, where the data points are represented as vectors. It then constructs a hyperplane in this space, which is used to separate the data into different classes. The goal of the SVM algorithm is to find the hyperplane that maximizes the margin between the data points of different classes
To do this, the SVM algorithm solves a quadratic optimization problem, which involves finding the values of the parameters that define the hyperplane in order to maximize the margin. This involves using a variety of mathematical techniques, such as gradient descent and the kernel trick, to optimize the hyperplane’s parameters and find the optimal solution
Overall, the math algorithm for an SVM involves solving a quadratic optimization problem in order to find the optimal hyperplane that separates the data into different classes. This involves using a variety of mathematical techniques (noted below) to optimize the hyperplane’s parameters and find the best solution.
Random Information: In a quadratic optimization problem, the objective function is of the form f(x) = x^TAx + b^Tx + c, where x is a vector of variables, A is a matrix, b is a vector, and c is a scalar. The goal of the optimization problem is to find the values of the variables in the vector x that minimize or maximize the objective function f(x).
What Is Sentiment Analysis In SEO?
All in all sentiment analysis is a subfield of natural language processing that involves analyzing the emotional content of a text, and determining whether it is positive, negative, or neutral in its underlying “tone.”
Sentiment analysis is often used in applications such as customer service, market research, and social media analysis, where it can provide valuable insights into people’s opinions and emotions.
For example, sentiment analysis can be used to identify trends and patterns in customer feedback, to understand how people feel about a product or service, or to monitor the sentiment of social media posts about a particular topic
Unlike entities that are noun-based, sentiment analysis depends heavily on adjectives and verbs, or words like:
- Love
- Hate
- Recommend
- Pleased
- Great
- Exceptional
Similarly to entity evaluation, sentiment analysis may include techniques such as part-of-speech tagging, named entity recognition, dependency parsing, and sentiment lexicons, which are lists of words and phrases that are associated with particular sentiments (noted above).
Machine learning algorithms may also be used to train a sentiment analysis model on a large corpus of annotated text, where the sentiment of each sentence or phrase has been labeled. This allows the model to learn the patterns and rules that are used to identify the sentiment in new text.


Page Contents
Other Blogs You May Be Interested In


Categories
Leave a Reply